
Structure de test
La structure de test adoptée pour ce tutoriel est celle du schéma de Polyhiérarchie.
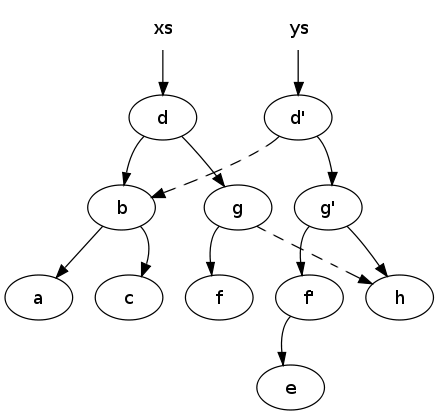
Les cercles tout en bas du schéma sont les articles. XS et YS sont les secteurs.

Une base de donnée exemple est jointe à l’article (dump SPIP 3, sans auteurs, avec juste les rubriques et les articles). Voilà la structure :
| ID | Titre |
|---|---|
| 1 | xs |
| 2 | d |
| 3 | b |
| 6 | ys |
| 7 | g |
| 8 | d’ |
| 10 | g’ |
| 11 | f’ |
| ID | Titre |
|---|---|
| 1 | f |
| 2 | a |
| 3 | c |
| 4 | e |
| 5 | h |
Ce qui donne le schéma suivant :
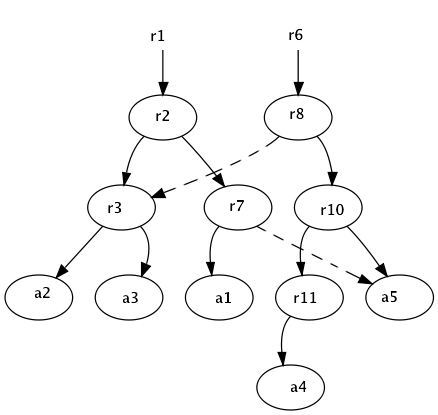
Les exemples que nous donnerons se baseront sur la recherche des chemins de l’article 5.
Principe général
Nous allons remonter les différentes hiérarchies depuis l’article jusqu’à la racine. Nous stockerons ces hiérarchies dans un tableau #ARRAY. Chaque entrée du tableau correspondant à un chemin possible, sous la forme rxryrx, où x, y, z sont les numéros de rubriques.
Puis nous bouclerons sur ce tableau, pour pouvoir gérer l’affichage des chemins. Chaque entrée sous la forme rxryrx sera transformée en tableau sur lequel nous bouclerons à l’envers (pour avoir une hiérarchie depuis le haut vers le bas, et non du bas vers le haut). Cela nous permettra d’afficher les chemins.
Nous utiliserons donc les outils les plus avancés du langage de squelette de SPIP :
- #ARRAY,#SET,#GET pour gérer le tableau.
- La boucle (POUR)
- Les boucles imbriquées pour pouvoir remonter entièrement la hiérarchie.
Je précise que cette contribution a été testée sous SPIP 3. Pour SPIP 2.1, il vous faudra installer le plugin BONUX.
Initialisation du tableau des chemins
Nous allons initialiser un tableau vide, où nous stockerons les différents chemins. Tout notre code devra être situé à l’intérieur d’une boucle ARTICLE.
Toujours à l’intérieur de cette boucle, nous allons initialiser une variable niveau qui nous permettra d’analyser à quelle niveau de hiérarchie nous sommes. Plus nous remonterons dans la hiérarchie, plus le niveau sera élevé. Nous partons du niveau 0.
<BOUCLE_article(ARTICLES){critères}>
#SET{chemins,#ARRAY}
#SET{niveau,0}
</BOUCLE_article>Remplissage du tableau, au premier niveau
Insérons maintenant dans cette boucle, après #SET{niveau,0} le code pour remplir le tableau pour le premier niveau de hiérarchie (comme toujours, en partant du bas) :
<BOUCLE_article(ARTICLES){critères}>
#SET{chemins,#ARRAY}
#SET{niveau,0}
<BOUCLE_parents(RUBRIQUES){parents}{par titre}>
#SET{n0,r#ID_RUBRIQUE}
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n0},
#GET{n0},
}
}}
</BOUCLE_parents>
</BOUCLE_article>Explications :
- nous stockons temporairement dans la variable n0 la valeur du chemin courant. En effet, nous en aurons besoin pour construire les chemins « au dessus » de cette rubrique.
- nous ajoutons dans le tableau, pour chaque rubriques « mère », une entrée dont la clef est rXXX et la valeur rXXX, où XXX représente le numéro de rubrique.
Pourquoi me direz vous dupliquer ainsi l’information ? Parce que si la rubrique courante a elle même des ancêtres, alors nous n’aurons pas un chemin complet. Par conséquence, il faudra effacer le « demi-chemin ». Nous en parlons plus loins. Chaque chose en son temps.
Pour le moment, notre tableau chemins se compose ainsi :
| Clef | Valeur |
|---|---|
| r7 | r7 |
| r10 | r10 |
Remonter la hiérarchie
Dans notre boucle _parents nous allons appeler une boucle _grands_parents, qui s’appellera de manière récursive, afin de remonter toute la hiérarchie.
Avant de rentrer dans cette boucle, nous allons augmenter la variable niveau de 1, et la rediminuer en sortant. Ainsi, nous saurons systématiquement à quelle niveau nous nous trouvons dans l’aborescence.
<BOUCLE_article(ARTICLES){critères}>
#SET{chemins,#ARRAY}
#SET{niveau,0}
<BOUCLE_parents(RUBRIQUES){parents}{par titre}>
#SET{n0,r#ID_RUBRIQUE}
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n0},
#GET{n0}
}
}}
#SET{niveau,#GET{niveau}|plus{1}}
<BOUCLE_grands_parents(RUBRIQUES){parents}{par titre}>
#SET{n#GET{niveau},#GET{n#GET{niveau}|moins{1}}r#ID_RUBRIQUE}
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}},
#GET{n#GET{niveau}}
}
}}
#SET{niveau,#GET{niveau}|plus{1}}
<BOUCLE_ancetres(Boucle_grands_parents) />
#SET{niveau,#GET{niveau}|moins{1}}
</BOUCLE_grands_parents>
#SET{niveau,#GET{niveau}|moins{1}}
</BOUCLE_parents>
Pour chaque niveau, noté x, nous allons créer une variable nx : c’est le #SET{n#GET{niveau},.
Cette variable reprendre la valeur de la variable nx-1, en ajoutant à la fin r#ID_RUBRIQUE : c’est le #GET{n#GET{niveau}|moins{1}}r#ID_RUBRIQUE.
Nous ajoutons ensuite la valeur de la variable nx comme couple entrée/valeur dans le tableau des chemins.
Enfin, nous remontons tout en haut de la hiérarchie par récursion, en appelant la boucle ancetres : voyez la documentation sur les boucles récursives.
Deux remarques pour prévenir les questions :
- Nous ne pouvons pas mettre le changement de la variable
niveaudans la partie optionelle des boucles, car cette partie est interprétée après le contenu de la boucle. - On pourrait se dire qu’il serait possible de commencer au niveau de la boucle
grand_parentset se passer deparents. Nous avons testé et obtenu des erreurs de récursions à l’infini, empêchant l’affichage de la page.
Notre tableau à maintenant le contenu suivant :
| r7 | r7 |
| r7r2 | r7r2 |
| r7r2r1 | r7r2r1 |
| r10 | r10 |
| r10r8 | r10r8 |
| r10r8r6 | r10r8r6 |
Filtrer les chemins incomplets
Les chemins r7,r7r2,r10, r10r8 ne sont pas complets : ils ne remontent pas jusqu’à la racine. Il nous faut donc les filtrer.
Pour ce faire, nous allons effacer la valeur de la clef correspondante, en mettant le code suivant dans la partie optionelle de nos boucles parents et grand_parents :
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}|moins{1}},
''
}
}}Cela donc donc :
<BOUCLE_article(ARTICLES){critères}>
#SET{chemins,#ARRAY}
#SET{niveau,0}
<BOUCLE_parents(RUBRIQUES){parents}{par titre}>
#SET{n0,r#ID_RUBRIQUE}
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n0},
#GET{n0}
}
}}
#SET{niveau,#GET{niveau}|plus{1}}
<BOUCLE_grands_parents(RUBRIQUES){parents}{par titre}>
#SET{n#GET{niveau},#GET{n#GET{niveau}|moins{1}}r#ID_RUBRIQUE}
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}},
#GET{n#GET{niveau}}
}
}}
#SET{niveau,#GET{niveau}|plus{1}}
<BOUCLE_ancetres(Boucle_grands_parents) />
#SET{niveau,#GET{niveau}|moins{1}}
}}
</BOUCLE_grands_parents>
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}|moins{1}},
''
}
}}
</B_grands_parents>
#SET{niveau,#GET{niveau}|moins{1}}
</BOUCLE_parents>
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}|moins{1}},
''
}
}}
</B_parents>
</BOUCLE_article>Et on a le tableau des chemins suivant :
| Clef | Valeur |
|---|---|
| r7 | |
| r7r2 | |
| r7r2r1 | r7r2r1 |
| r10 | |
| r7r2r8 | |
| r7r2r8r6 | r7r2r8r6 |
Afficher tout les chemins
L’essentiel est fait : il ne nous reste plus qu’à boucler sur le tableau des chemins, en excluant ceux dont la valeur est vide :
<B_chemins>
<ul>
<BOUCLE_chemins(POUR){tableau #GET{chemins}}{valeur!=''}>
<li>#VALEUR</li>
</BOUCLE_chemins>
</ul>
</B_chemins>Cela produit :
<ul>
<li>r7r2r1</li>
<li>r10</li>
<li>r7r2r8r6</li>
</ul>Chaque li correspond à un chemin. Il nous faut donc l’afficher.
Pour ce faire, nous allons :
- exploser la chaînes rxryrz pour obtenir un tableau, en utilisant r comme séparateur.
- boucler sur ce tableau, en insérant une symbole de séparation entre chaque entrée, en évitant les entrées vides (liées au fait que nous n’avons pas de r à la fin de nos chemin) et en inversant l’ordre (pour avoir une hiérarchie allant de haut en bas et non de bas en haut)
- dans la boucle, récupérer le titre la rubrique avec la balise #INFO_TITRE, et son URL avec #URL_RUBRIQUE{x}
.
Ce qui donne :
<B_chemins>
<ul>
<BOUCLE_chemins(POUR){tableau #GET{chemins}}{valeur!=''}>
<B_chemin>
<li>
<a href="#URL_SITE_SPIP">#NOM_SITE_SPIP</a> >
<BOUCLE_chemin(POUR){tableau #VALEUR|explode{r}}{inverse}{valeur!=''}{" > "}>
<a href="#URL_RUBRIQUE{#VALEUR}">#INFO_TITRE{rubrique,#VALEUR}</a>
</BOUCLE_chemin>
> #TITRE [(#REM)<!-- correspond au titre de l'article-->]
</li>
</B_chemin>
</BOUCLE_chemins>
</ul>
</B_chemins>Et en HTML produit :
<ul>
<li>
<a href="http://poly.dev">Mon site SPIP</a> >
<a href="-rubrique1-.html">xs</a>
>
<a href="-rubrique2-.html">d</a>
>
<a href="-rubrique7-.html">g</a>
> h
</li>
<li>
<a href="http://poly.dev">Mon site SPIP</a> >
<a href="-rubrique6-.html">ys</a>
>
<a href="-rubrique8-.html">d’</a>
>
<a href="-rubrique10-.html">g’</a>
> h
</li>
</ul>Mettre en exergue le chemin principal
Il serait pratique que le chemin principal s’affiche en premier, avec une classe spéciale. Pour ce faire, nous allons utiliser une boucle HIERARCHIE classique, qui affichera le chemin avant, et stockera dans une variable cheminp ce chemin, afin de pouvoir l’exclure des chemins sur lesquelles on boucle.
Le remplissage de cette variable et l’affichage du chemin se fait donc ainsi :
<B_cheminp>
<div class='cheminp'>
<a href="#URL_SITE_SPIP">#NOM_SITE_SPIP</a> >
<BOUCLE_cheminp(HIERARCHIE){id_article}{" > "}>
<a href="#URL_RUBRIQUE}">#TITRE</a>[(#SET{cheminp,[r(#ID_RUBRIQUE)][(#GET{cheminp})]})]
</BOUCLE_cheminp>
> #TITRE [(#REM)<!-- correspond au titre de l'article-->]
</div>
</B_cheminp>Nous allons donc exclure de la boucle chemins le chemin dont la valeur est égale à #GET{cheminp}.
Ce qui donne :
<B_chemins>
<ul>
<BOUCLE_chemins(POUR){tableau #GET{chemins}}{valeur!=''}{valeur!=#GET{cheminp}}>
<B_chemin>
<li>
<a href="#URL_SITE_SPIP">#NOM_SITE_SPIP</a> >
<BOUCLE_chemin(POUR){tableau #VALEUR|explode{r}}{inverse}{valeur!=''}{" > "}>
<a href="#URL_RUBRIQUE{#VALEUR}">#INFO_TITRE{rubrique,#VALEUR}</a>
</BOUCLE_chemin>
> #TITRE [(#REM)<!-- correspond au titre de l'article-->]
</li>
</B_chemin>
</BOUCLE_chemins>
</ul>
</B_chemins>Au final
Nous avons donc au final un ensemble de boucles qui s’écrivent ainsi :
<BOUCLE_article(ARTICLES){critères}>
#SET{chemins,#ARRAY}
#SET{niveau,0}
<BOUCLE_parents(RUBRIQUES){parents}{par titre}>
#SET{n0,r#ID_RUBRIQUE}
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n0},
#GET{n0}
}
}}
#SET{niveau,#GET{niveau}|plus{1}}
<BOUCLE_grands_parents(RUBRIQUES){parents}{par titre}>
#SET{n#GET{niveau},#GET{n#GET{niveau}|moins{1}}r#ID_RUBRIQUE}
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}},
#GET{n#GET{niveau}}
}
}}
#SET{niveau,#GET{niveau}|plus{1}}
<BOUCLE_ancetres(Boucle_grands_parents) />
#SET{niveau,#GET{niveau}|moins{1}}
</BOUCLE_grands_parents>
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}|moins{1}},
''
}
}}
</B_grands_parents>
#SET{niveau,#GET{niveau}|moins{1}}
</BOUCLE_parents>
#SET{chemins,#GET{chemins}|array_merge{#ARRAY{
#GET{n#GET{niveau}|moins{1}},
''
}
}}
</B_parents>
#SET{cheminp,''}
<B_cheminp>
<div class='cheminp'>
<a href="#URL_SITE_SPIP">#NOM_SITE_SPIP</a> >
<BOUCLE_cheminp(HIERARCHIE){id_article}{" > "}>
<a href="#URL_RUBRIQUE}">#TITRE</a>[(#SET{cheminp,[r(#ID_RUBRIQUE)][(#GET{cheminp})]})]
</BOUCLE_cheminp>
> #TITRE [(#REM)<!-- correspond au titre de l'article-->]
</div>
</B_cheminp>
<B_chemins>
<ul>
<BOUCLE_chemins(POUR){tableau #GET{chemins}}{valeur!=''}{valeur!=#GET{cheminp}}>
<B_chemin>
<li>
<a href="#URL_SITE_SPIP">#NOM_SITE_SPIP</a> >
<BOUCLE_chemin(POUR){tableau #VALEUR|explode{r}}{inverse}{valeur!=''}{" > "}>
<a href="#URL_RUBRIQUE{#VALEUR}">#INFO_TITRE{rubrique,#VALEUR}</a>
</BOUCLE_chemin>
> #TITRE [(#REM)<!-- correspond au titre de l'article-->]
</li>
</B_chemin>
</BOUCLE_chemins>
</ul>
</B_chemins>
</BOUCLE_article>Ce qui donne en HTML
<div class='cheminp'>
<a href="http://poly.dev">Mon site SPIP</a> >
<a href="-rubrique6-.html}">ys</a>
>
<a href="-rubrique8-.html}">d’</a>
>
<a href="-rubrique10-.html}">g’</a>
> h
</div>
<ul>
<li>
<a href="http://poly.dev">Mon site SPIP</a> >
<a href="-rubrique1-.html">xs</a>
>
<a href="-rubrique2-.html">d</a>
>
<a href="-rubrique7-.html">g</a>
> h
</li>
</ul>Le reste n’est plus qu’affaire de maîtrise du CSS / HTML.
Aucune discussion
Ajouter un commentaire
Avant de faire part d’un problème sur un plugin X, merci de lire ce qui suit :
Merci d’avance pour les personnes qui vous aideront !
Par ailleurs, n’oubliez pas que les contributeurs et contributrices ont une vie en dehors de SPIP.
Suivre les commentaires : |
|
