

Les avantages de ce plugin
- permettre de définir des temps de cache tres longs dans les squelettes, et eviter de rafraichir régulièrement des squelettes expirés "par vieillesse" (utilisation non nécessaire des ressources du serveur).
- permettre de rafraichir uniquement les caches concernés par des modification du site.
- optionellement rafraichir les pages en tâches de fond, et non pas devant les utilisateurs.
- rafraichir les pages nécessaires en temps voulu. Si un article est programmé à la publication dans le futur, on rafraichira les pages affectées à ce moment précis.
Il propose de plus quelques outils pratiques pour éliminer des éléments du cache de manière ciblée.
Pour ceux qui utilisent un fournisseur de CDN, ce plugin intègre une invalidation chez Cloudflare, Edgecast et Akamai. Pour ceux qui n’en utilisent pas (ce qui doit être le cas en général), il vous suffira d’ignorer les parties qui mentionnent le CDN.
Ce plugin, associé à une bonne connaissance et organisation de vos squelettes, permet un taux de rafraichissement de votre site optimal. Il est principalement destiné aux sites à gros traffic et/ou à vaste contenu, qui ne peuvent pas se permettre de repartir à zéro de façon régulière en terme de cache.
Principe des systèmes Pull/Push
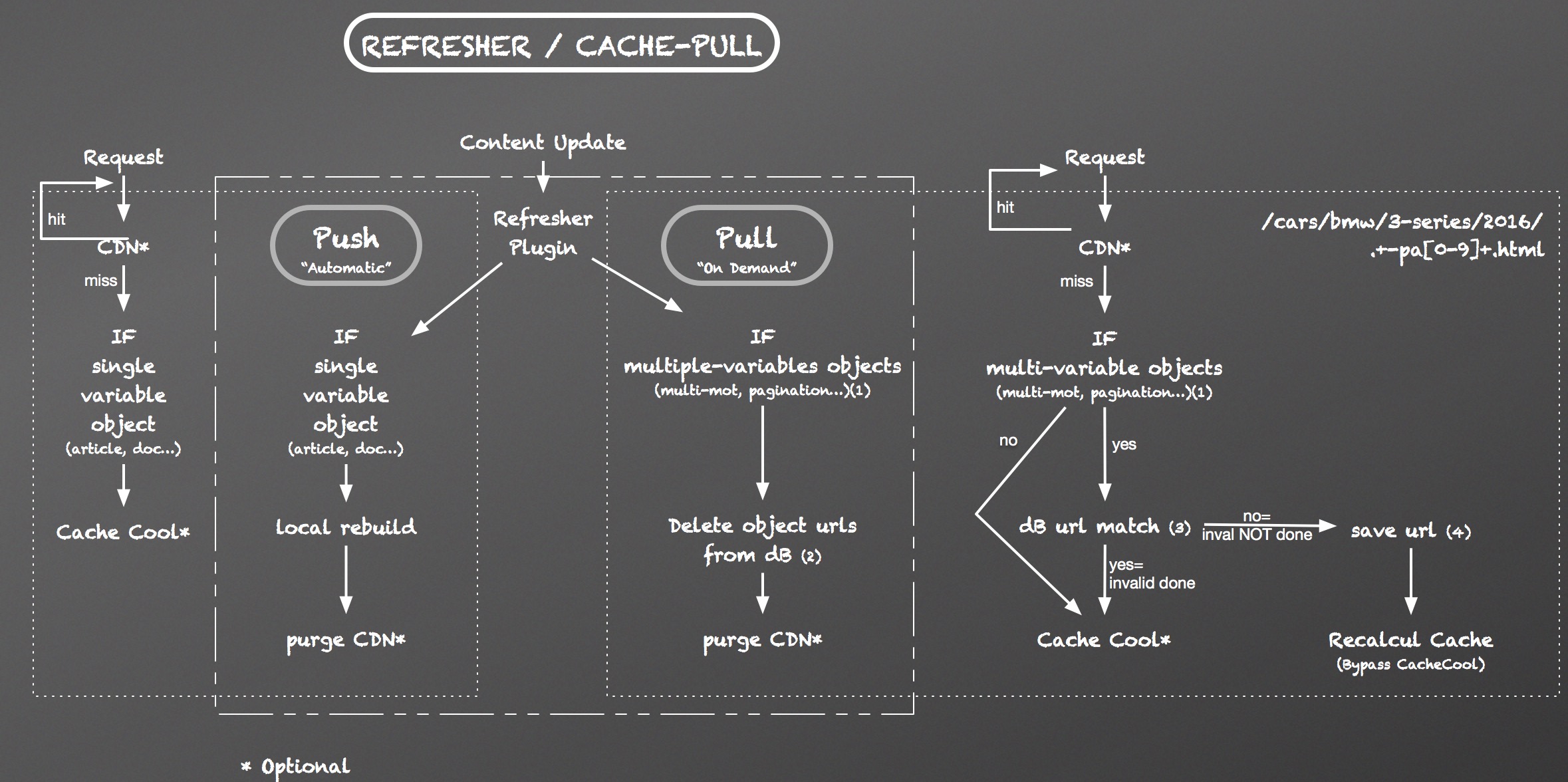
Ce plugin permet d’invalider les pages du site de deux façons : en mode “Pull” ou “Push”, qui peuvent être utilisées conjointement sur un même site, pour des jeux de page différentes :
- La technique “Pull” consiste en une invalidation des pages (via leurs URLs), et l’attente de la prochaine visite sur ces pages pour reconstruire leur cache (devant le visiteur). Le cache est ici construit à la demande.
- En mode “Push” on va recalculer la page en tache de fond, sans nécessairement que la page soit visitée. Ainsi dans cette méthode nous forçons un calcul du cache afin que les visiteurs éventuels profitent d’un cache déjà prêt, même lors de la première visite qui suit l’invalidation.
IMPORTANT :
- Pour le “Pull”, il suffit de connaître le nom du squelette principal des pages et de l’objet invalidé.
- Pour le “Push”, il faut être en mesure de déterminer exactement les URLs des pages a invalider.
La méthode “Pull” est utile quand :
- il est difficile de déterminer les URLs à modifier (car le “Push” nécessite de connaître les URLs exacts)
- on a un très grand nombre d’URLs à invalider (ne pas charger le job_queue avec un tas de pages a calculer)
- les pages à invalider sont rarement visitées et/ou invalidées tres fréquemment (peu de chances de visite entre deux invalidations, evitons de pre-calculer pour rien).
- il importe peu si les pages sont recalculées devant le visiteur (un bot ?)
La méthode “Push” est utile quand :
- on a peu d’URLs à invalider et on peut les déterminer précisément
- les pages sont assez lourdes à calculer, (mais pas trop nombreuses) afin d’ éviter une longue attente pour le prochain visiteur.
- les pages concernées sont fréquemment visitées (si on est certain qu’une page va être visitée, autant la préparer).
- on veut contrôler la charge du serveur, car les pré-calculs sont gérés par le job_queue, et à une fréquence définie dans la configuration du plugin.
Cas typique d’utilisation du ’Pull’ :
Une rubrique paginée qui doit etre intégralement invalidée, dont la liste d’URLs est difficile a déterminer (ou la pagination s’arrête-t’elle ?), et peut-être longue. De plus, en général, plus on avance dans la pagination et moins une page a de chances d’être visitée. Il se peut qu’un grand nombre de ces pages ne soient même pas visitées avant la prochaine invalidation de cette rubrique.
Cas typique d’utilisation du “Push” :
La page d’accueil du site.
Installation
Ce plugin s’installe classiquement, et ne nécessite aucun autre plugin. Une fois le plugin activé, l’invalidation globale du site après une action éditoriale sera désactivée (celle utilisée par défaut dans SPIP). Les rafraichissements ne prendront toutefois effet qu’une fois ceux-ci configurés dans la page de configuration du plugin.
Le plugin utilise job_queue afin de gérer la file d’URLs à rafraichir, mais job_queue est maintenant integré à SPIP depuis la version 3.0.
Le plugin est compatible avec le CacheCool, mais il en limite l’utilite.
Options basiques
- autoriser le plugin à effectuer des rafraichissements de cache SPIP (Push).
Cette option va faire en sorte que les URLs soient recalculés afin de rafraichir le contenu de leur page. Pour cela nous traitons chaque URL dans la file en la chargeant à l’aide de la librairie PHP CURL (qui doit être installée sur votre serveur si vous utilisez cette option). Le paramètre var_mode=calcul est passé avec la methode POST. Cela nous permet de passer au travers du CDN dans le cas ou vous en utilisez un.
- autoriser le plugin à faire des purges sur le CDN, si vous en utilisez un.
Cloudflare, Akamai et Edgecast proposent des API pour effectuer des purges de cache ciblées. Nous pouvons ainsi invalider un URL en particulier, ce qui ne mettra que quelques secondes à prendre effet sur les serveurs du CDN. Il suffit de fournir les informations demandées dans la page de configuration. Ces informations vous sont fournies par votre prestataire CDN. L’utilisation de la purge CDN nécessite l’extension CURL pour PHP. Vous pouvez utiliser la purge CDN sans utiliser le rafraichissement du cache SPIP si vous le souhaitez (et si cela a du sens dans votre configuration).
- Liste de groupes de mots clés à rafraichir.
Nous vous demandons de sélectionner les groupes de mots clés dont les mots clés possèdent leur propre page sur le site, afin de ne pas mettre à jour des pages de mots clés qui n’existent pas. Nous partons du principe que les mots clés d’un même groupe ont le même comportement et que cette sélection est suffisante.
- Qui peut utiliser var_mode=recalcul dans les URLs ?
Pourquoi cette option ? Pourquoi pas ? Vous ne souhaitez peut être pas que n’importe qui puisse recalculer vos pages. Et si pour une raison obscure Google se mettait à crawler votre site en utilisant ce paramètre ?
- Temps de pause entre chaque rafraichissement (Push).
Il est recommandé de mettre un temps de pause, même faible, entre les rafraichissements, afin de ne pas créer de subite surcharge du serveur. Ceci est important si vous utilisez le rafraichissement du cache SPIP (calcul), si des actions éditoriales entrainent le rafraichissement de nombreux URLs et si certaines de ces pages ont des calculs lourds. De plus, certains CDN ont un nombre limite de requetes vers leur API par minute.
Créer des règles d’invalidations de type ’Pull’
La méthode de “Pull” utilise une table dans la base de données. Elle se remplira d’URLs de votre site une fois que vous aurez créé des règles de type “Pull”. Dans refresher_options.php, il faut créer une variable globale, qui est un tableau de règles. Une règle consiste en un squelette (le squelette principal d’une page) et d’un objet. Dès lors, si on tombe sur une page qui utilise ce squelette et cet objet, soit cet URL est déjà dans la table (cache valide), soit il est absent, et on enregistre l’URL dans la table et recalcule les caches. Lors des invalidations, nous retrouvons toutes les pages liées à un objet et on les supprime de la table.
Prenons un exemple. Nous souhaitons être capables d’invalider les pages liées a un mot clé si on ajoute un article à ce mot. Dans ce cas, il faut créer la règle suivante :
$GLOBALS['refresher_objets'] = array(
array('mot_skel','mot')
);Dans mon système, la page d’un mot clé utilise le squelette “mot_skel”. Ainsi, dès que l’on tombera sur l’une de ces pages, on enregistre l’URL ainsi que l’id_mot associé à cet URL. Lors d’une invalidation, il suffira d’indiquer au plugin de rafraîchir les mots associés aux articles, et l’ajout d’un article va invalider toutes les URLs des mots associés à cet article. Il est à noter que les objets peuvent être des objets non-SPIP, et les identifiants peuvent être des chaines de caractères.
Rafraichissements simples (mode Push)
La page de configuration du plugin permet de sélectionner des rafraichissements simples et qui me paraissent les plus évidents. Nous pourrons améliorer cette liste avec les impressions des utilisateurs, mais fournir une liste infinie de cas de figures et de liens possibles à rafraichir n’est pas le but, car avec un peu de PHP nous pouvons cibler de manière tres précise nos besoins en rafraichissements et personaliser ce plugin (voir “Rafraichissements avancés”). Pour ma part je n’utilise aucune de ces options à cocher.
Rafraichissements avancés
Le plugin possède un système similaire aux pipelines SPIP, ainsi pour chaque action éditoriale, nous pouvons créer une fonction PHP qui prendra en paramètre un tableau d’URLs, et retourne ce même tableau une fois qu’on lui aura ajouté nos URLs à rafraichir. Il est soit possible d’ajouter directement des URLs a ce tableau, soit des associations “id_objet|objet” (chaine de charactères sous cette forme).
Push :
- URL -> va rafraichir cet URL dans le job_queue
- id_objet|objet -> va rafraichir l’URL de cet objet (ce que retournerait la balise #URL_XXXXXX, par exemple #URL_MOT)
Pull :
- URL -> va invalider cet URL specifique, si il est dans le système
- id_objet|objet -> va chercher tous les URLs du système qui correspondent a cet objet si on lui a defini des regles de ’Pull’
Ainsi, si vous avez des besoins très particuliers en matière de mises à jour lors de l’édition d’un article (édition d’un champs, par exemple), vous pouvez créer une fonction “refresh_objet_modifier_article”, soit dans mes_fonctions.php ou dans refresher_options.php, ou encore refresher_functions.php (assurez vous juste de faire au mieux pour votre propre organisation). Cette fonction aura cette allure :
function refresh_objet_modifier_article($urls, $id_article, $arr){
...
//insertion de mes URLs à rafraichir dans $urls
...
return $urls;
}À l’intérieur de cette fonction, il vous suffira de réccupérer les URLs que vous souhaitez rafraichir, en considérant que la connaissance de l’identifiant de l’article qui est modifié vous le permet.
Si par exemple, je souhaite rafraichir la page de la rubrique de l’article ainsi que la homepage :
function refresh_objet_modifier_article($urls, $id_article, $arr){
// rafraichir la rubrique en “Push”
$res = sql_select("id_rubrique", "spip_articles", "id_article=".intval($id_article), "", "", 1);
if($row = sql_fetch($res)) array_push($urls['push'], $row['id_rubrique'].'|rubrique');
//rafraichir la homepage (url vide ou “/”) en “Push”
array_push($urls['push'],'');
//rafraichir l'article en “Pull”
array_push($urls['pull'], $id_article.'|article');
return $urls;
}À noter que le paramètre $arr contient les informations de mise à jour interceptées dans les pipelines post_edition et pre_edition (c’est exactement le même paramètre que celui passé à ces pipelines). Vous pouvez analyser le contenu de ce tableau pour faire des rafraichissements encore plus pointus si vous le souhaitez.
Rafraichir la rubrique de l’article lors de sa modification est disponible depuis la page de configuration dans les rafraichissements basiques, ce code est juste à titre d’exemple. Si toutefois pour une raison ou une autre le même URL apparaît plusieurs fois dans le processus, les doublons seront éliminés et l’URL ne sera rafraichi qu’une seule fois.
voici une liste des fonctions principales que vous pouvez créer (il y en a d’autres non listées, et d’autres à venir) . Elles fonctionnent toutes sur le modèle évoqué plus haut :
refresh_objet_instituer_article($urls, $id_article, $arr)
- > traite le changement de statut d’un article ainsi que son changement de date. En gros cela correspond a la publication/suspension d’un article sur le site.
refresh_objet_modifier_article($urls, $id_article, $arr)
refresh_objet_modifier_document($urls, $id_document, $arr)
refresh_objet_modifier_rubrique($urls, $id_rubrique, $arr)
refresh_objet_modifier_mot($urls, $id_mot, $arr)
- > à priori tout autre objet éditable fonctionnera de la même manière, à tester...
refresh_lien_delete_document_article($urls, $id_document, $id_article, $arr)
refresh_lien_insert_document_article($urls, $id_document, $id_article, $arr)
- > à priori tout autre objet associable à un document fonctionnera de la même manière, à tester...
refresh_lien_delete_mot_article($urls, $id_mot, $id_article, $arr)
refresh_lien_insert_mot_article($urls, $id_mot, $id_article, $arr)
- > à priori tout autre objet associable à un mot fonctionnera de la même manière, à tester...
Outils de nettoyage du cache
Les points suivants concernent le second onglet dans la configuration du plugin. Il s’agit de quelques outils partiques pour gérer le cache.
- Vider la file d’attente d’URLs à rafraichir
Cette fonctionnalité permet de vider la file d’attente des URLs à rafraichir dans le job_queue.
- Supprimer des fichiers cache SPIP en fonction de leur nom
Cette fonction peut s’avérer plus intéressante qu’elle n’en a l’air. Elle permet dans un premier temps de vider les répertoires du cache un par un, ce qui peut être pratique si l’on souhaite purger le cache mais de manière légèrement progressive afin de ne pas avoir subitement tout le site à reconstruire. Plus subtilement encore, elle permet dans certains cas de supprimer les caches correspondant à un squelette en particulier. En effet dans certains cas, le système de nommage des fichiers cache nous permet d’identifier quel squelette ils contiennent. Les fichiers cache sont nommés de maniere peu lisible mais avec une certaine logique, à partir du nom de squelettes et des paramètres, entre autres.
Prenons un exemple concret sur mon site, j’ai un squelette article.html, et avec un peu de manipulation PHP je me suis aperçu que sur une page prise au hasard le nom de fichier généré est ’art-mar-ast-mar-rap-s-ar-2bea7d03’ :
- le ’art’ de debut correspondant au nom du squelette article.html
- la suite étant générée à partir du titre de l’article et les caracteres de fin sont le résultat d’un calcul md5
Il se trouve que cette logique s’applique à tous mes articles similaires à cette page, ainsi je peux supprimer tous ces caches en utilisant la fonction du backend et en mettant dans le champs le nom de fichier “art-*”.
Il est ainsi possible de supprimer des caches correspondants à certains squelettes ou certains parametres sans pour autant avoir à purger tout le cache du site. Cela demande un peu d’astuce mais s’avère pratique.
- Supprimer des fichiers cache SPIP en fonction de leur date
Ceci est une autre fonction extrêmement utile si l’on ne peut pas se permettre de se débarrasser de son cache. Prenons le simple exemple où vous vous rendez compte après plusieurs jours que vous avez fait une erreur significative dans vos squelettes. Cette erreur s’est maintenant répandue dans vos caches et soit vous attendez que vos pages se rafraichissent naturellement (laissant donc l’erreur trainer un certain temps), soit vous purgez votre cache et votre serveur va prendre une charge que vous auriez volontiers évité. Il suffit d’utiliser cette fonction pour supprimer tous les caches créés pendant la période entre la mise à jour malencontreuse et le moment présent. Votre site est donc nettoyé avec un impact minimum sur votre serveur.
- Rafraichir un URL manuellement
Suivant les options activées dans le premier onglet du plugin, cela vous permet de manière ponctuelle de rafraichir une page dans le cache SPIP et/ou purger l’URL sur le CDN. Pour ce qui est de mettre a jour le cache SPIP, cela revient à taper manuellement “var_mode=calcul” dans votre URL. Mais cela est très pratique lorsque vous utilisez un CDN car vous pouvez ainsi pour n’importe quelle raison invalider l’URL que vous souhaitez sur les serveurs du CDN (cela prendra plusieurs secondes avant d’être effectif sur tous les serveurs du CDN). Un autre cas de figure est si vous n’autorisez pas l’utilisation de la variable “var_mode=(re)calcul” sur le site public. Cette fonctionnalité passe au travers car elle envoie le “var_mode=calcul” dans une variable de type POST.
Rafraichissements réguliers
Il s’agit ici du troisième onglet de la configuration du plugin. Cette fonctionalité permet de programmer à intervalles reguliers des mises a jour de certaines pages (en “Push”). Le temps d’intervalle est à définir en minutes. La marge d’erreur est de 5 minutes, c’est à dire qu’en pratique, un intervalle entre deux rafraichissements d’URLs peut être jusqu’à 5 minutes plus long que la valeur définie par l’utilisateur. Ceci est du au fait que la tâche de fond principale du plugin ne s’effectue que toutes les 5 minutes afin de ne pas encombrer la file.
Optimisations et remarques
Ce systeme est créé afin d’éviter de générer des rafraichissements inutiles. Par exemple si un article est modifié mais n’est pas encore publié sur le site (on teste le statut et la date), le système n’effectuera pas de rafraichissement. Si un article est programmé pour une publication, cela entrainera des rafraichissements à la date précise de cette publication. Mais si l’on modifie cette date par la suite, les rafraichissements programmés precedemment seront annulés et de nouveaux seront enregistrées dans job_queue avec la nouvelle date. Gérer tous ces cas est toutefois complexe et il est possible que des cas de figure aient été négligés à ce jour.
C’est à la responsabilité du programmeur de cibler de maniere précise ces rafraichissements lors de l’utilisation des pipelines afin de ne pas charger inutilement le serveur. Il est de plus recommandé de préparer ses articles au maximum à l’avance (contenu, documents, mots clés) et de programmer la publication au dernier moment, ce qui limitera les risques de laisser passer des mises à jour.
Astuce pour rafraichir un bloc isolé
Il se peut que vous veuillez rafraichir un bloc sans connaître sa position dans votre site, mais en connaissant ses paramètres. Un cas concret serait un bloc article dans une rubrique qui a une pagination.
rubrique.html :
...
<BOUCLE_page(ARTICLES){id_rubrique}{par date}{inverse}{pagination 10}>
...
<INCLURE{fond=bloc_article}{id_article}{parametre1}{parametre2}>
...
</BOUCLE_page>
...Dans le cas de la modification d’un article, vous voulez rafraichir ce bloc, mais pas toutes les pages de la rubrique (charge inutile, voire insupportable si la rubrique est vaste). Il suffit de créer un squelette dédié au rafraichissement de ce bloc, en vous assurant simplement que tous les paramètres sont identiques et repris dans le même ordre, afin de mettre à jour le bon fichier en cache.
refresh_bloc_article.html :
<INCLURE{fond=bloc_article}{id_article}{parametre1}{parametre2}>Vous pouvez placer ce squelette dans votre répertoire squelettes, ou bien dans la racine du repértoire du plugin refresher, puisque ce squelette fait en quelques sortes partie du plugin.
Ainsi il ne vous restera qu’à écrire ce code dans le pipeline :
function refresh_objet_modifier_article($urls, $id_article, $arr){
array_push($urls['push'], "spip.php?page=refresh_bloc_article&id_article=".$id_article);
return $urls;
}Puisque le squelette refresh_bloc_article.html utilise exactement le même bloc_article que rubrique.html, il va écraser le cache, et peu importe où le bloc se trouve dans votre pagination il sera à jour sans que l’on ait à se soucier de recalculer les pages de la rubrique. Cela est d’autant plus pratique si ce bloc_article figure dans plus d’une rubrique, car vous pouvez tout mettre a jour en un seul rafraichissement d’URL.
Aucune discussion
Ajouter un commentaire
Avant de faire part d’un problème sur un plugin X, merci de lire ce qui suit :
Merci d’avance pour les personnes qui vous aideront !
Par ailleurs, n’oubliez pas que les contributeurs et contributrices ont une vie en dehors de SPIP.
Suivre les commentaires : |
|
